
数据分析师培训班靠谱吗-{下拉词
大家好,今天小编关注到一个比较有意思的话题,就是关于数据分析师培训班靠谱吗的问题,于是小编就整理了6个相关介绍数据分析师培训班靠谱...


扫一扫用手机浏览
大家好,今天小编关注到一个比较有意思的话题,就是关于spark 数据分析的问题,于是小编就整理了3个相关介绍spark 数据分析的解答,让我们一起看看吧。

Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。简而言之,sparkSQL是Spark的前身,是在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具。
sparkSQL提供了一个称为DataFrame(数据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
SparkSql有哪些特点呢?
1)引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。
2)在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
3)内嵌了查询优化框架,在把SQL解析成逻辑执行***之后,最后变成RDD的计算。
技术方案:
1、***用分布式集群结构的数据分析系统,对接各类数据源(超大数据量sql、抽样数据库等)实时汇总、分析;
2、***用大数据实时流数据处理技术,实现实时处理流数据;
3、***用数据分析平台,支持多种数据格式,实现数据分析挖掘、可视化展示;
4、***用API接口方式,实现系统数据接口对接,实现不同系统数据之间的交互;
5、***用Hadoop和Spark等技术,实现大规模数据分析和挖掘;
6、***用NoSQL数据库(MongoDB),实现原始数据的存储,并实现子数据查询和报表展示;
7、***用定时任务异步框架,实现系统的定时任务,实现定时计算统计信息;
8、***用接口对接技术,实现与第三方数据系统的集成,实现统计数据的自动获取。
Spark技术从之前和当前的技术路线上看不是为了替代Hadoop,更多的是作为Hadoop生态圈(广义的Hadoop)中的重要一员来存在和发展的。
首先我们知道Hadoop(狭义的Hadoop)有几个重点技术HDFS、MR(MapReduce), YARN。
这几个技术分别对应分布式文件系统(负责存储), 分布式计算框架(负责计算), 分布式***调度框架(负责***调度)。
我们再来看Spark的技术体系 ,主要分为以下:
- Spark Core :提供核心框架和通用API接口等,如RDD等基础数据结构;
- Spark SQL : 提供结构化数据处理的能力, 分布式的类SQL查询引擎;
- Streaming: 提供流式数据处理能力;
- GraphX : 提供图计算能力
从上面Spark的生态系统看,Spark主要是提供各种数据计算能力的(官方称之为全栈计算框架),本身并不过多涉足存储层和调度层(尽管它自身提供了一个调度器),它的设计是兼容流行的存储层和调度层。也就是说, Spark的存储层不仅可以对接Hadoop HDFS,也可以对接Amazon S2; 调度层不仅可以对接Hadoop YARN也可以对接(Apache Mesos)。
因此,我们可以说Spark更多的是补充Hadoop MR单一批处理计算能力, 而不是完全替代Hadoop的。
【关注ABC(A:人工智能;B:BigData; C: CloudComputing)技术的攻城狮,Age:10+】
到此,以上就是小编对于spark 数据分析的问题就介绍到这了,希望介绍关于spark 数据分析的3点解答对大家有用。
[免责声明]本文来源于网络,不代表本站立场,如转载内容涉及版权等问题,请联系邮箱:83115484@qq.com,我们会予以删除相关文章,保证您的权利。
大家好,今天小编关注到一个比较有意思的话题,就是关于数据分析师培训班靠谱吗的问题,于是小编就整理了6个相关介绍数据分析师培训班靠谱...
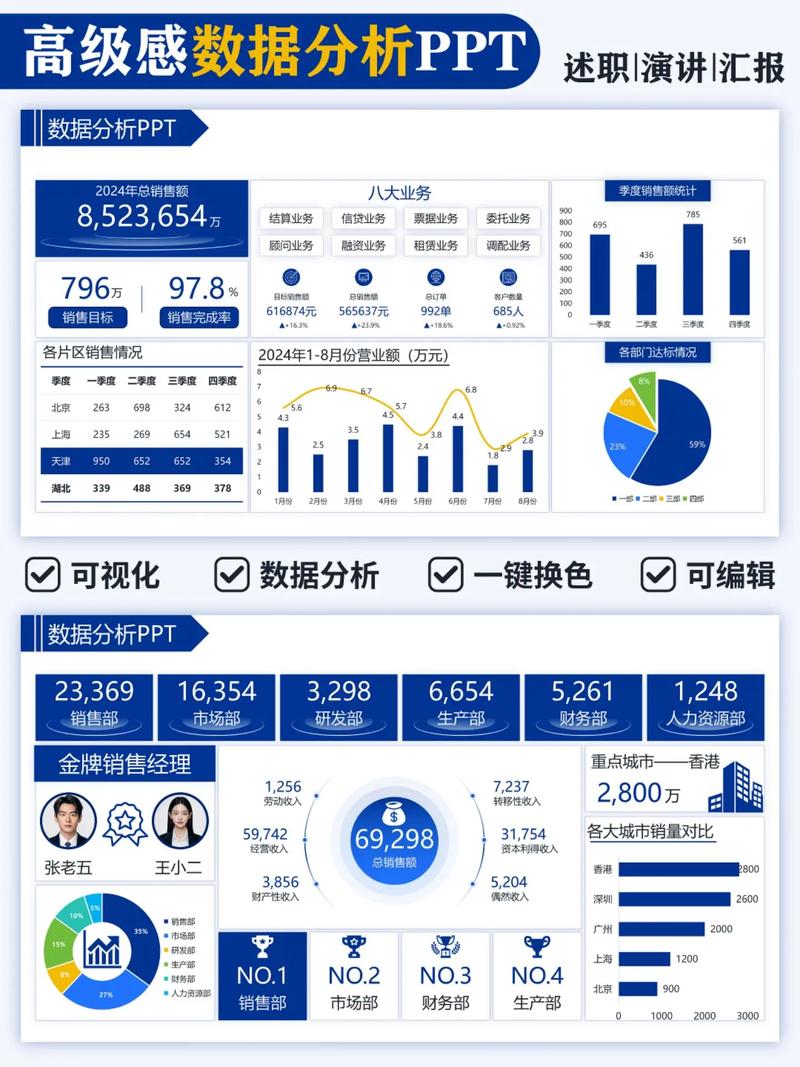
数据分析的目的是什么 1、通过面向企业业务场景提供一站式大数据分析解决方案,能够为企业在增收益、降成本、提效率、控成本等四个角度带...